
8 - Types#
Record Types#
A record is a possibly heterogeneous aggregate of data elements in which the individual elements are identified by names.
Definition of Records in COBOL#
COBOL uses level numbers to show neested records; others use recursive definition.
01 EMP-REC.
02 EMP-NAME.
05 FIRST PIC X(20).
05 MID PIC X(10).
05 LAST PIC X(20).
02 HOURLY-RATE PIC 99V99.
References to Records#
Record field references:
COBOL:
field_name OF record_name_n OF ... OF record_name_1Others (dot notation):
record_name_1.record_name_2....record_name_n.field_name
Fully qualified references must include all record names.
Elliptical references allow leaving out record names as long as the reference is unambiguous, for example, in COBOL, FIRST, FIRST OF EMP-NAME, and FIRST OF EMP-REC are elliptical references to the employee’s first name.
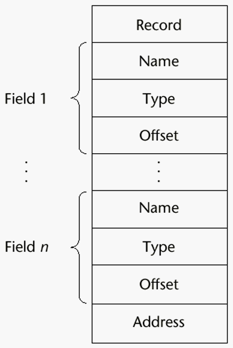
Implementation of Record Types#
Offset address relative to the beginning of the records is associated with each field.
Tuple Types#
A tuple is a data type that is similar to a record, except that the elements are not named. It is used in Python, ML, and F# to allow functions to return multiple values.
In Python,
Closely related to lists, but immutable
Created with a tuple literal
myTuple = (3, 5.8, 'apple)Referenced with subscripts
Catenation with
+and deletion withdel
In ML,
val myTuple = (3, 5.8, 'apple');#1(myTuple)returns the first elementA new type of tuple can be defined:
type intReal = int * real;
In F#,
let tup = (3, 5, 7)let a, b, c = tup: This assigns a tuple to a tuple pattern
List Types#
Lists in Lisp and Scheme are delimited by parantheses and use no commas ((A B C D) and (A (B C) D)).
Data and code have the same form:
As data,
(A B C)is literally what it isAs code,
(A B C)is the functionAapplied to the parametersBandC
The interpreter needs to know which a list is, so if it is data, we quote it with an apostraphe: '(A B C) is data.
In addition to the examples below, C# and Java support lists through their generic heap-dynamic collection class List and ArrayList, respectively.
Lists in Scheme#
CARreturns the first element of its list parameter:(CAR '(A B C))returnsACDRreturns the remainder of its list parameter after the first element has been removed:(CDR '(A B C))returns(B C)CONSputs its first parameter into its second parameter, a list, to make a new list:(CONS 'A (B C))returns(A B C)LISTreturns a new list of parameters:(LIST 'A 'B '(C D))returns(A B (C D))
Lists in ML#
Lists are written in brackets and the elements are separated by commas
List elements must be of the same type
The Scheme
CONSfunction is a binary operator in ML,:::3 :: [5, 7, 9]evaluates to[3, 5, 7, 9]The Scheme
CARandCDRfunctions are namedhdandtl, respectively
Lists in F##
Lists in F# are like those of ML, except elements are separated by semicolons and hd and tl are methods of the List class.
Lists in Python#
The list data type also serves as Python’s arrays
Unlike Scheme, Common Lisp, ML, and F#, Python’s lists are mutable
Elements can be of any type
Create a list with assignment:
myList = [3, 5.8, 'apple]List elements are referenced with subscripting, with indices beginning at zero
List comprehensions, which are derived from set notation:
[x * x for x in range(9) if x % 3 == 0]creates[0, 9, 36]Haskell also has list comprehensions:
[n * n | n <- [1..10]]So does F#:
let myArray = [|for i in 1 .. 5 -> (i * i) |]
Union Types#
A union is a type whose variables are allows to store difference type values at different times during execution.
Discriminated vs. Free Unions#
C and C++ provide union constructs where there is no language support for type checking; the union in these languages is called free union.
Type checking of unions require that each union include a type indicator called a discriminator/tag. These are are supported in ML, Haskell, and F#.
Union Types in C/C++#
typedef struct tagINPUT {
DWORD type;
union {
MOUSEINPUT mi;
KEYBDINPUT ki;
HARDWAREINPUT hi;
} DUMMYUNIONNAME;
} INPUT, *PINPUT, *LPINPUT
Union Types in F##
type Shape =
| Rectangle of width : float * length : float
| Circle of radius : float
| Prism of width : float * length : float * height : float;;
let getShapeWidth shape =
match shape with
| Rectangle(width = w) -> w
| Circle(radius = r) -> 2. * r
| Prism(width = w) -> w;;
Pointer and Reference Types#
A pointer type variable has a range of values that consists of memory addresses and a special value, nil. Pointers provide ways to indirectly address variables and to access locations where storage is dynamically created (the heap).
Pointer Operations#
There are 2 fundamental pointer operations: assignment and dereferencing.
Assignment is used to set a pointer variable’s value to some useful address.
Dereferencing yields the value stored at the location represented by the pointer’s value
Dereferncing can be explicit or implicit
C++ uses an explicit operation via
*j = ptr, which setsjto the value located atptr
Pointer asignment:

Problems with Pointers#
Dangling pointers:
A pointer points to a heap-dynamic variable that has been deallocated
Lost heap-dynamic variable:
An allocated heap-dynamic variable that is no longer accessible to the user program (often called garbage)
Pointer
p1is set to point to a newly created heap-dynamic variablePointer
p1is later set to point to another newly created heap-dynamic variableThe process of losing heap-dynamic variables is called memory leakage
Pointers in C and C++#
Extremely flexible, but must be used with care
Pointers can point at any variable regardless of when or where it was allocated
Pointer arithmetic is possible
Explicit dereferencing and address-of operators
Domain type need not be fixed (
void *)void *can point to any type checked (cannot be dereferenced)
Pointer arithmetic in C/C++:
float stuff[100];
float *p;
p = stuff;
int i;
x = p + 5; // Equal to stuff[5] and p[5]
y = p + i; // Equal to stuff[i] and p[i]
Reference Types#
C++ includes a special type kind of pointer type called a reference type that is used primarily for formal parameters. This allows for the advantages of both pass-by-reference and pass-by-value.
Java extends C++’s reference variables and allows them to replace pointers entirely. References are references to objects rather than addresses.
C# includes both the references of Java and the pointers of C++.
Evaluation of Pointers#
Dangling pointers and dangling objects are problems
Pointers are like
gotos, in that they widen the range of cells that can be accessed by a variablePointers or references are necessary for dynamic data structures, so we can’t design a language without them
Dangling Pointer Problem#
A tombstone is an extra heap cell that is a pointer to the heap-dynamic variable.
The actual pointer variable points only at tombstones
When the heap-dynamic variable is deallocated, the tombstone remains set to nil
Costly in time and space
Locks-and-keys are pointer values that are represented as (key, address) pairs.
Heap-dynamic variables are represented as variable plus cell for integer lock value
When heap-dynamic variables are deallocated, the lock value is created and placed in the lock cell and key cell of the pointer
Heap Management#
A very complex run-time process
Single-size cells vs. variable-size cells
Two approaches to reclaim garbage:
Reference counters (eager approach): reclamation is gradual
Mark-sweep (lazy approach): reclamation occurs when the list of variable space becomes empty
Reference Counter#
Reference counters are counters in every cell that that store the number of pointers currently pointing at the cell.
Disadvantages: space required, execution time required, complications for cells connected circularly
Advantage: it is intrinsically incremental, so significant delays in the application execution are avoided
Mark-Sweep#
In the mark-sweep approach, the run-time system allocates storage cells as requested and disconnects pointers from cells as necessary. Then, the mark-sweep begins:
Every heap cell has an extra bit used by collection algorithm
All cells initially set to garbage
All pointers traced into heap, and reachable cells are marked as not garbage
Disadvantages: in its original form, it was done too infrequently. When done, it caused significant delays in application execution. Contemporary mark-sweep algorithms avoid this by doing it more often, often called incremental mark-sweep